
windows环境下安装elasticsearch
每个es有对应的jdk版本,如果本地已经配置jdk环境变量,需要单独设置,
具体官方教程:elasticsearch官方使用教程
历史版本下载:elasticsearch历史版本下载
各版本兼容览表:elasticsearch兼容览表
注意:非系统盘安装elasticsearch的目录不能有空格,不然后续安装其他插件时找不到路径
比如我是es 7.10.2版本,在bin目录下修改elasticsearch.bat文件指定自带jdk目录
@echo off
setlocal enabledelayedexpansion
setlocal enableextensions
::添加这句话
set "JAVA_HOME=D:\Program\elasticsearch-7.10.2\jdk"
如果是更高的版本,需要在环境变量中添加"ES_JAVA_HOME"指定自带jdk目录
如果电脑配置较低,可以修改堆内存大小,进入config目录修改jvm.options文件,找到-Xms和-Xmx去掉##注释,比如我只需要512m。
-Xms512m
-Xmx512m
# 启动
进入bin目录,点击elasticsearch.bat文件即可
等到打印started,访问http://localhost:9200/查看是否成功
# 安装ElasticSearch-head插件
1、需要node环境,执行cmd命令检查是否安装,没有则自行安装。
node -v
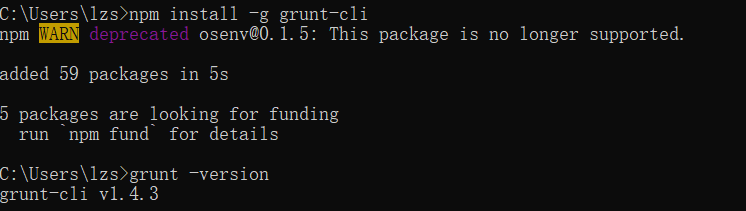
2、安装 Grunt 工具(node环境下)
npm install -g grunt-cli
执行cmd查看是否成功
grunt -version
3、安装ElasticSearch-head,逐步执行以下cmd命令符(第一条需要git环境,要么单独下载项目)
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
访问 http://localhost:9100/,看到页面代表成功,但集群概览为空,需要配置elasticsearch允许跨域才行
修改elasticsearch目录下config/elasticsearch.yml文件,尾部追加以下内容,重启elasticsearch.bat能看到集群健康值
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: "*"
# 安装 kibana
启动es访问http://localhost:9200/查看es信息,下载Kibana的版本version和build必须和elasticsearch对应【oss代表开源版本,商业:Basic、Standard、Gold、Platinum】

例如我当前下载版本:对应7.10.2和oss版本

下载地址:Kibana各版本
进入kibana/bin目录,点击kibana.bat启动
访问 http://localhost:5601检查是否成功
中文版界面:
修改 config\kibana.yml 文件,将 i18n.locale: “en”, 改为 i18n.locale: “zh-CN”
# 安装ik中文分词器
下载地址:https://release.infinilabs.com/analysis-ik/stable/
1、需要下载与elasticsearch一样的版本,下载好压缩包放到elasticsearch目录下
2、启动elasticsearch
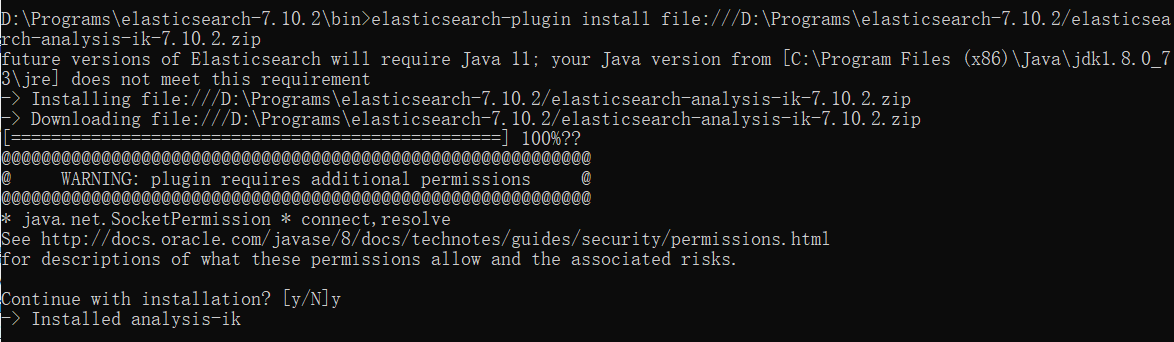
3、新打开cmd窗口进入elasticsearch/bin目录,执行安装命令(file:///后面是安装包路径)
elasticsearch-plugin install file:///D:\Programs\elasticsearch-7.10.2/elasticsearch-analysis-ik-7.10.2.zip
4、验证安装,bin目录下执行cmd命令,会看到插件列表
elasticsearch-plugin list
5、测试ik分词器,启动kibana访问http://localhost:5601/,找到Dev Tools页面,输入内容
GET _analyze
{
"analyzer": "ik_smart",
"text": "lzs博客教程"
}
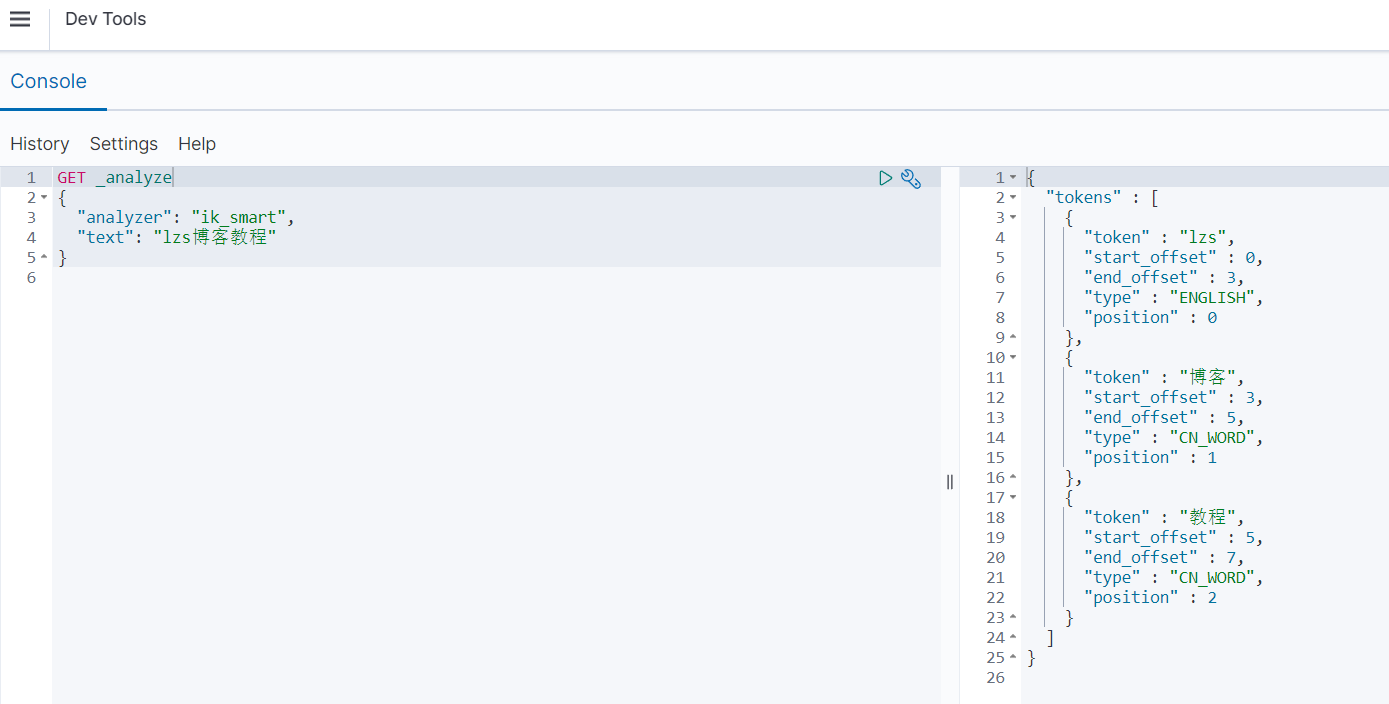
_analyze:分词器名称(固定)
ik_max_word:允许句子的字反复出现,只要这些字在词库中出现过,就会被拆分出来
ik_smart:在分词时,每个字在句子里只会出现一次
tetx:需要分词文本
## 创建一个ik分词器索引,其中content执行ik规则
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"ik_max_word": {
"type": "custom",
"tokenizer": "ik_max_word"
},
"ik_smart": {
"type": "custom",
"tokenizer": "ik_smart"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
## PUT /my_index:创建一个名为my_index的索引。
## settings:配置索引的设置。这里定义了两个自定义分析器ik_max_word和ik_smart,它们使用IK分词器。
## mappings:定义索引的映射。在这个示例中,有一个字段content,类型为text,使用ik_max_word作为索引时的分析器,ik_smart作为搜索时的分析器。
自定义分词器字典
进入elasticsearch-7.10.2\config\analysis-ik目录,自定义创建文件“custom.dic”,内容写你需要的分词(正常情况下springboot是不会拆分的,但是自定义字典后,会拆分成springboot、spring、boot)
Springboot
Spring
boot
打开IKAnalyzer.cfg.xml文件,修改内容,追加字典文件
<?xml version="1.0" encoding="UTF-8"?>
<properties>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom.dic</entry>
</properties>
# es的一些用法
_search 是用于执行搜索请求的固定端点
- query: 用于定义查询部分。
- match: 一种查询类型,用于执行全文搜索。
- term: 用于精确匹配的查询。
- range: 用于范围查询。
- bool: 用于组合多个查询条件。
- must, should, must_not: 在bool查询中使用,用于定义必须匹配、应该匹配或必须不匹配的条件。
- filter: 用于过滤结果的条件。
## 搜索单个索引index1中的文档
POST /index1/_search
## 搜索多个索引中的文档
POST /index1,index2/_search
## 搜索整个集群中的文档
POST /_search
{
"query": {
"match": {
"content": "国歌"
}
}
}
_doc 是用于操作单个文档(创建、更新、删除、获取)的固定端点
## 创建或更新文档1(存在id为1则更新,否则新增)
POST /my_index/_doc/1
{
"content": "中华人民共和国国歌"
}
## 创建一个自动生成ID的文档
POST /my_index/_doc
{
"content": "中华人民共和国国歌"
}
## 获取文档1
GET /my_index/_doc/1
## 删除文档1
DELETE /my_index/_doc/1
创建索引
## 简单索引
PUT /my_index
## 更新该索引的副本分片为0(单机不需要)
## number_of_replicas副本分片,number_of_shards主分片
PUT /my_index/_settings
{
"index": {
"number_of_replicas":0
}
}
_cat 端点
_cat 端点提供了对集群、索引、节点等信息的简单和易读的输出。它通常用于检索和监视集群的健康状态、节点信息和索引统计等。
- 查看集群健康状况:GET /_cat/health?v
- 查看节点信息:GET /_cat/nodes?v
- 查看索引列表:GET /_cat/indices?v
_cluster 端点
_cluster 端点用于管理集群级别的操作和设置。
- 查看集群状态:GET /_cluster/state
- 查看集群健康状况:GET /_cluster/health
- 查看集群设置:GET /_cluster/settings
_aliases 端点
_aliases 端点用于管理索引的别名。
- 获取别名信息:GET /_aliases
- 创建或更新别名:POST /_aliases
- 删除别名:DELETE /_aliases
_bulk 端点
_bulk 端点用于批量操作文档的添加、更新和删除。
- 批量添加文档:POST /_bulk
- 批量更新文档:POST /_bulk
- 批量删除文档:POST /_bulk
_snapshot 端点
_snapshot 端点用于管理和操作快照(备份和恢复)。
- 创建快照存储库:PUT /_snapshot/my_backup
- 创建快照:PUT /_snapshot/my_backup/snapshot_1
- 恢复快照:POST /_snapshot/my_backup/snapshot_1/_restore
其他端点
除了上述常见端点外,还有一些专门用于监控、管理和安全的端点,如:
_nodes:用于节点相关的信息和操作。
_tasks:用于查看和管理正在执行的任务。
_sql:用于执行 SQL 查询。
_ingest:用于管道处理(Ingest Pipeline)。